


风暴注册
风暴资讯
这篇文章的方法还是比较好理解的,

三句话概括,
如果进一步把 slow weights 的表达式展开,
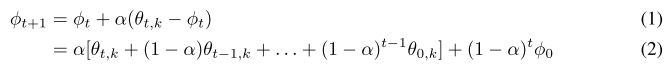
这里的 是 第
轮 fast weights 更新的第
步(也就是最后一步)。这个叫
Exponential Moving Average~(EMA),对后面理论证明会有一点用。(如果只是想了解这个算法,这个地方可以跳过)
fast weights 的更新就是正常的 SGD,你可以选择任何想用的优化器,当然包括 Adam。
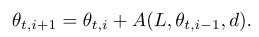
上面说,fast weights 的更新,就是正常 SGD,所以用什么 learning rate 就不在本文的套路范围内了。但是 slow weight 的更新,方向我们知道了,就是跟随 fast weight 更新的方向 。就像这个图一样,

那他的 learning rate 就是一个比较重要的待确定的值了。作者先是对一个简单的 quadratic problem 给出了 optimal 的解,
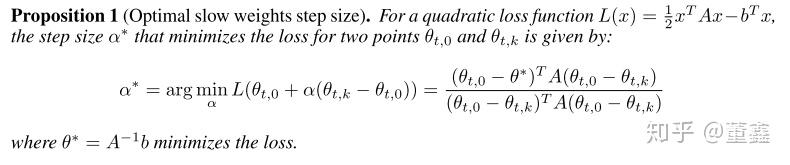
然后提出,其实一个固定的 也是可以达到差不多的收敛效果的。
在 Cifar 的实验中,

在 ImageNet 的实验中,

作为一篇讲优化器的文章,完备的实验自然是必不可少的。作者跑了 CIFAR,ImageNet,LSTM 还有 Transformer。具体的结果在论文中找到,基本上作者并没有 report 拔群的准确率,但是稳定性倒是强调不少。
这里想提一下其中一个小实验,
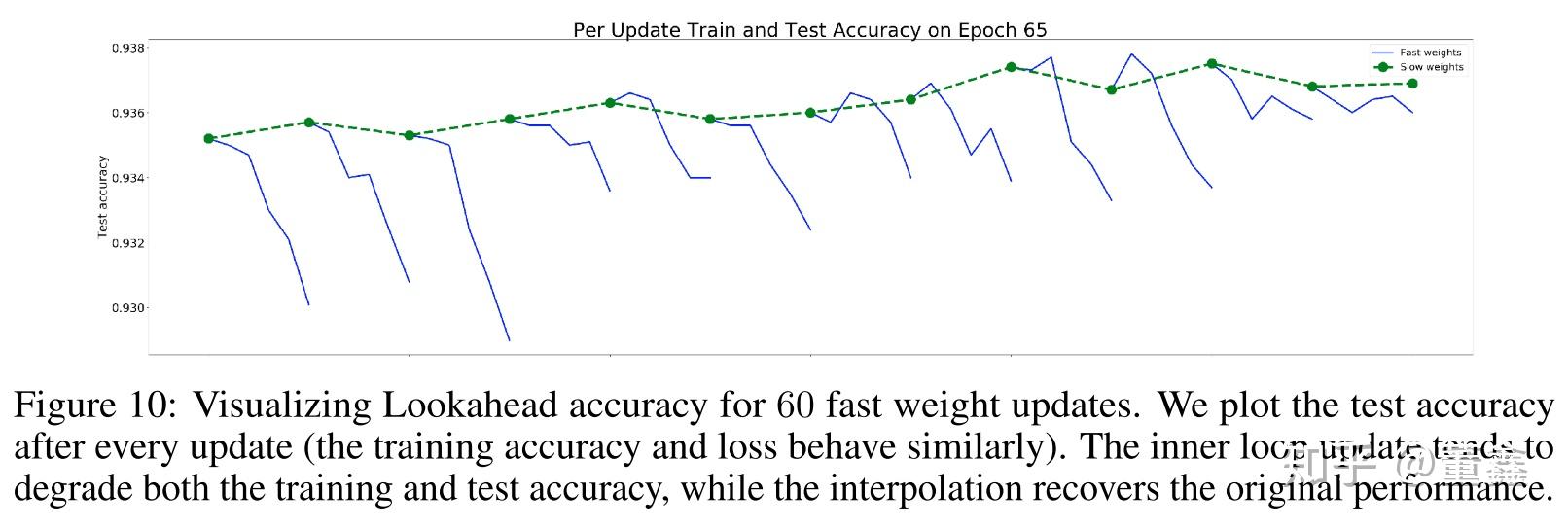
在 Epoch 65 的时候,这个时候网络的性能已经很不错了,稍微动一下 fast weight 可以看到,其实都是对网络的 test acc 是副作用(蓝色的线)。但是因为有 slow weights 的存在,能够把这种副作用拉回来。作者也是希望通过这幅图说明,Lookahead 一个最重要的卖点还是能够提高稳定性,然优化过程更加 robust。


