


风暴注册
风暴资讯
在深度模型中我们通常需要设计一个模型的代价函数(或损失函数)来约束我们的训练过程,训练不是无目的的训练,而是朝着最小化代价函数的方向去训练的。本文主要讨论的就是这类特定的优化问题:寻找神经网络上一组参数 ,它能显著地降低代价函数
,该代价函数通常包括整个训练集上的性能评估和额外的正则化项。
在这篇文章里深度学习的前戏--梯度下降、反向传播、激活函数,我们曾探讨过梯度下降问题,说明了在深度学习中最小化代价函数的方法就是重复计算代价函数在训练集上的梯度,从而使得参数 往梯度相反的方向更新,以使得代价函数取到最小值。
设 是每个样本的损失函数,
是输入 x 时所预测的输出,
是数据生成分布,
是目标输出,于是得到目标函数:
机器学习算法的目标就是降低上式所示的期望泛化误差,这个数据量被称为风险。但是实际中,我们是无法知道数据的真实分布 的,我们只有有限的训练数据,能得到的也只有训练数据样本的分布,也称为经验分布
,因此在实际优化问题中,我们需要使用经验分布来代替真实分布,于是目标函数为:
因此我们需要最小化经验风险:
其中 m 表示训练样本的数目。基于最小化这种平均训练误差的训练过程被称为经验风险最小化(empirical risk minimization)。
但是直接最小化经验风险很容易导致过拟合,于是我们需要在经验风险后面加一个正则化项,在这篇文章中我们详细介绍了几种常用的正则化方法 深度学习中的正则化技术--L1&L2-norm,Dropout,Max-norm,像这种加了正则化项的风险函数我们称为结构风险函数,于是我们的优化目标变为最小化结构风险函数。
我们在计算最小化经验风险的时候,从它的计算公式可以看出,它需要计算训练集上每个样本的损失(或者梯度),然后求和;当训练样本非常大时(特别是在深度学习中)这将是非常耗时间的。统计知识告诉我们“整体期望可以用随机抽取的样本期望来进行无偏估计”,那么直觉的可以想到是不是可以在训练样本中随机采样少量样本,然后计算这些样本上的风险平均值来代替整体的风险平均值呢?事实上,m个样本均值的标准差是 ,具体计算公式如下:
其中m表示样本个数, 是样本的真实标准差,分母
表明使用更多样本来估计梯度的方法的回报是低于线性的。 比较两个假想的梯度计算,一个基于 100 个样本,另一个基于 10, 000 个样本。后者需要的计算量是前者的 100 倍,但却只降低了 10 倍的均值标准差。如果能够快速地计算出梯度估计值,而不是缓慢地计算准确值,那么大多数优化算法会收敛地更快。
另外由于训练集存在的冗余现象,在最坏的情况下,训练样本所有的m的样本都是彼此的相同拷贝,基于采样的梯度估计可以使用单个样本计算出正确的梯度,而比原来的做法少花了 m 倍时间。虽然实际中不可能遇到这种最坏的情况,但仍然会存在大量样本都对梯度做出了非常相似的贡献。
使用整个训练集的优化算法被称为批量或确定性的梯度算法(如,梯度下降算法),这种算法代价非常高昂。使用训练集的随机采样样本的优化算法称为小批量梯度算法,在深度模型中我们有充足理由选择小批量梯度算法:
使用小批量梯度算法需要注意的是:1)抽取小批量前对样本进行随机打乱顺序,有些算法对采样误差比较敏感,一个是它们使用了很难在少量样本上精确估计的信息,另一个是它们以放大采样误差的方式使用了信息;2)两个连续的小批量应该相互独立:从一组样本中计算出梯度期望的无偏估计要求这些样本是独立的;3)最好多次遍历数据集:在算法遍历数据集更新参数时,只有第一遍满足泛化误差梯度的无偏估计(因为第一遍遍历时,每一批小样本都是从数据流中抽取出来的。 换言之,学习器好像是一个每次看到新样本的人,每个样本 都来自数据生成分布
,而不是使用大小固定的训练集。这种情况下,样本永远不会重复;每次更新的样本是从分布
中采样获得的无偏样本。)额外的遍历对参数的更新虽然是有偏的估计,但是它会因减小训练误差而得到足够的好处来抵消其带来的训练误差和测试误差间差距的增加。
优化是一个很困难的任务,在传统机器学习中一般会很小心的设计目标函数和约束,以使得优化问题是凸的;然而在训练神经网络时,我们遇到的问题大多是非凸,这就给优化带来更大的挑战。
凸优化问题通常可以简化为寻找一个局部极小值点的问题,在凸函数中,任何一个局部极小点都是全局最小点;有些凸函数的底部是一个平坦区域,在这个平坦区域的任一点都是一个可以接受的解。如下图所示:
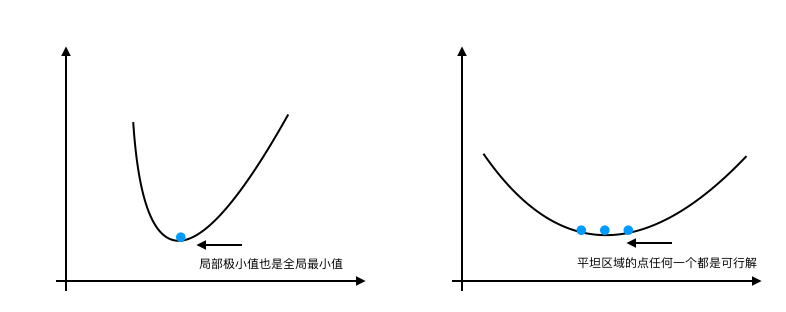
但是在非凸函数中,梯度经常卡在局部极小值点出不来,所以得不到全局最优解,如下图所示:
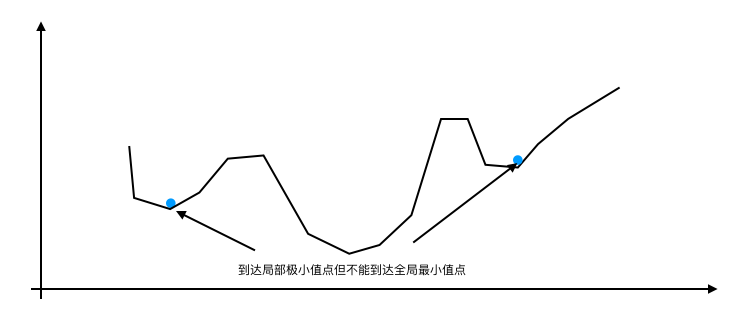
低维空间中,局部极小值很普遍。在更高维空间中,局部极小值很罕见,而鞍点则很常见。鞍点处的极值也为0,在鞍点处,Hessian 矩阵同时具有正负特征值。位于正特征值对应的特征
向量方向的点比鞍点有更大的代价,反之,位于负特征值对应的特征向量方向的点有更小的代价,从而神经网络也不能优化到一个极小值。我们可以将鞍点视为代价函数某个横截面上的局部极小点,同时也可以视为代价函数某个横截面上的局部极大点,如下图红色小点所示:
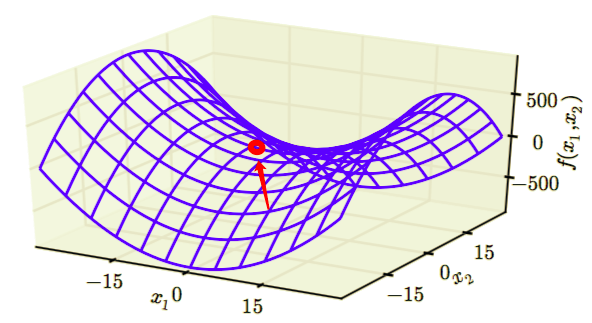
另外如果在高原处,梯度是平坦的,那么优化算法很难知道从高原的哪个方向去优化来减小梯度,因为平坦的高原处每个方向的梯度都是0。高维空间的这种情形为优化问题带来很大的挑战。
多层神经网络通常存在像悬崖一样的斜率较大区域,如下图所示。这是由于几个较大的权重相乘导致的。遇到斜率极大的悬崖结构时,梯度更新会很大程度地改变参数值,通常会完全跳过这类悬崖结构。
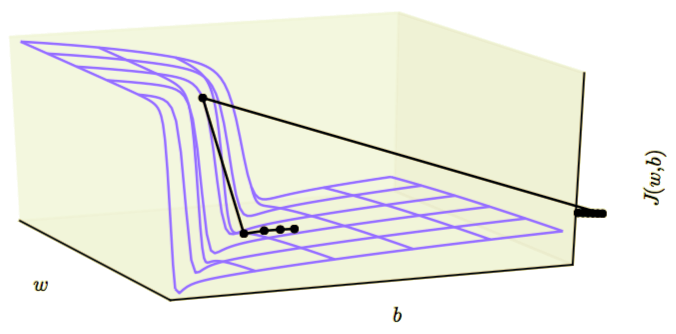
高度非线性的深度神经网络或循环神经网络的目标函数通常包含由几个参数连乘而导致的参数空间中尖锐非线性。这些非线性在某些区域会产生非常大的导数。当参数接近这样的悬崖区域时,梯度下降更新可以使参数弹射得非常远,可能会使大量已完成的优化工作成为无用功。
当计算图变得极深时,神经网络优化算法会面临的另外一个难题就是长期依赖问题——由于变深的结构使模型丧失了学习到先前信息的能力,让优化变得极其困难。深层的计算图不仅存在于前馈网络,还存在于循环网络中。因为循环网络要在很长时间序列的各个时刻重复应用相同操作来构建非常深的计算图,并且模型参数共享,这使问题更加凸显。
例如,假设某个计算图中包含一条反复与矩阵 相乘的路径。那么 t 步后,相当于乘以
。假设
有特征值分解
。在这种简单的情况下,很容易看出
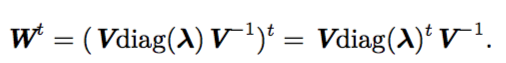
当特征值 λi 不在 1 附近时,若在量级上大于 1 则会爆炸;若小于 1 时则会消失。梯度消失与爆炸问题(vanishing and exploding gradient problem)是指该计算图上的 梯度也会因为 大幅度变化。梯度消失使得我们难以知道参数朝哪个方向移动能够改进代价函数,而梯度爆炸会使得学习不稳定。之前描述的促使我们使用梯度截断的悬崖结构便是梯度爆炸现象的一个例子。
比如非精确梯度,局部和全局结构间的弱对应,优化的理论限制等。
训练深度神经网络经常需要花费很多时间,在本文开头介绍了之前写的两篇文章,我们可以知道一般加快神经网络训练速度的方法有:合适的初始化策略,使用合适的激活函数;还可以使用批量归一化处理每层的输出数据,也可以使用预训练好的模型做迁移学习。这里我们介绍一些常用的优化算法,这能非常有效的缩短梯度下降所需要的时间,这些优化算法包括:SGD, Momentum optimization, Nesterov Accelerated Gradient, AdaGrad, RMSProp, and Adam optimization。
我们已经很熟悉梯度下降算法了,随机梯度下降(SGD)其实就是通过数据生成分布随机抽取m个小批量样本,在这些小批量样本上应用梯度下降算法通过计算它们的梯度均值来得到梯度的无偏估计。

动量可以加速学习,特别是处理高曲率、小但一致的梯度,或是带噪声的梯度。动量算法积累了之前梯度指数级衰减的移动平均,并且继续沿该方向移动。动量的效果如下图所示
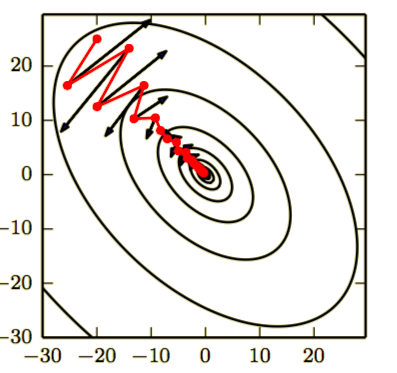
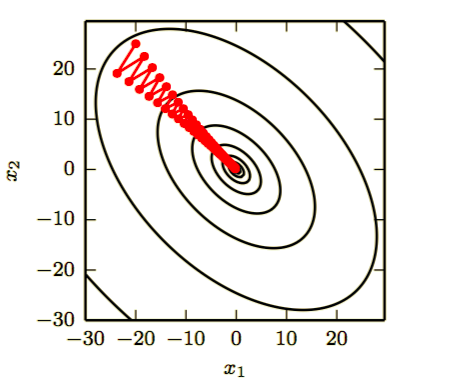
横跨轮廓的红色路径表示动量学习规则所遵循的路径,它使该函数最小化。我们在该路径的每个步骤画一个箭头,表示梯度下降将在该点采取的步骤。我们可以看到,一个病态条件的二次目标函数看起来像一个长而窄的山谷或具有陡峭边的峡谷。动量正确地纵向穿过峡谷,而普通的梯度步骤则会浪费时间在峡谷的窄轴上来回移动。比较下图,它也显示了没有动量的梯度下降的行为。
动量算法引入了变量 v 充当速度角色,它的作用是如果当前梯度越大,那么此时参数更新幅度越大,更新规则如下:
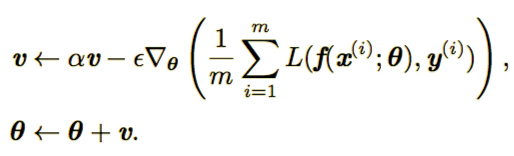
具体算法如下图所示:

在梯度下降算法中,步长等于梯度范数乘以学习率,而现在步长取决于梯度序列的大小和排列。当许多连续的梯度指向相同的方向时,步长最大。如果动量算法总是能观测到梯度 g ,那么它会在方向 -g 上不停加速,知道达到最终速度,其中步长大小为: ,如果动量超参数设置为
,则对应着最大速度10倍于梯度下降算法。
optimizer = tf.train.MomentumOptimizer(learning_rate=learning_rate,
momentum=0.9)Nesterov 动量和标准动量之间的区别体现在梯度计算上。Nesterov 动量中,梯度计算在施加当前速度之后。因此,Nesterov 动量可以解释为往标准动量方法中添加了一个校正因子。完整的 Nesterov 动量算法如下所示。

参数更新规则为:
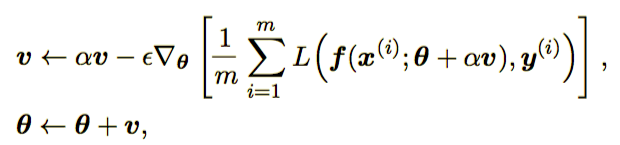
optimizer = tf.train.MomentumOptimizer(learning_rate=learning_rate,
momentum=0.9, use_nesterov=True)由于学习率对模型的性能有显著影响,又比较难以设置,于是有了自适应学习率算法。 AdaGrad算法,如下图所示,独立地适应所有模型参数的学习率,缩放每个参数反比于其所有梯度历史平方值总和的平方根。具有损失最大偏导的参数相应地有一个快速下降的学习率,而具有小偏导的参数在学习率上有相对较小的下降。净效果是在参数空间中更为平缓的倾斜方向会取得更大的进步。 然而,经验上已经发现,对于训练深度神经网络模型而言,从训练开始时积累梯度平方会导致有效学习率过早和过量的减小。AdaGrad 在某些深度学习模型上效果不错,但不是全部。

RMSProp 算法修改 AdaGrad 以在非凸设定下效果更好,改变梯度积累为指数加权的移动平均。AdaGrad 旨在应用于凸问题时快速收敛。当应用于非凸函数训练神经网络时,学习轨迹可能穿过了很多不同的结构,最终到达一个局部是凸碗的区域。AdaGrad 根据平方梯度的整个历史收缩学习率,可能使得学习率在达到这样的凸结构前就变得太小了。RMSProp 使用指数衰减平均以丢弃遥远过去的历史,使其能够在找到凸碗状结构后快速收敛,它就像一个初始化于该碗状结构的 AdaGrad 算法实例。
RMSProp 的标准形式如算法 8.5 所示,结合 Nesterov 动量的形式如算法 8.6 所
示。相比于 AdaGrad,使用移动平均引入了一个新的超参数ρ,用来控制移动平均的
长度范围。
经验上,RMSProp 已被证明是一种有效且实用的深度神经网络优化算法。目前
它是深度学习从业者经常采用的优化方法之一。


optimizer = tf.train.RMSPropOptimizer(learning_rate=learning_rate,
momentum=0.9, decay=0.9, epsilon=1e-10)Adam 是另一种学习率自适应的优化算法,如算法 8.7 所示。“Adam’’ 这个名字派生自短语 “adaptive moments’’。

首先,在 Adam 中,动量直接并入了梯度一阶矩(指数加权)的估计。将动量加入 RMSProp 最直观的方法是将动量应用于缩放后的梯度。结合缩放的动量使用没有明确的理论动机。其次,Adam 包括偏置修正,修正从原点初始化的一阶矩(动量项)和(非中心的)二阶矩的估计(算法 8.7 )。RMSProp 也采用了(非中心的)二阶矩估计,然而缺失了修正因子。因此,不像 Adam,RMSProp 二阶矩估计可能在训练初期有很高的偏置。Adam 通常被认为对超参数的选择相当鲁棒,尽管学习率有时需要从建议的默认修改。
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)在训练深度神经网络模型时,Adam 优化算法可以被优先选择,它通常比其他优化算法快并且效果好;Adam 算法有三个参数,一般使用默认的参数就可以了,但是如果需要调整的话,建议熟悉一下它的理论,然后根据实际情况设置参数。
1、Aure?lien Ge?ron,《 Hands-On Machine Learning with Scikit-Learn and TensoFlow》
2、 Ian Goodfellow et. al,《Deep Learning》


