


风暴注册
风暴资讯
pytorch 可以说是最简单易学的深度学习库了,为了加快神经网络的学习效率我们通常会使用一些加速技巧,但很多人都是使用的torch.optim自带的优化器,本文就将介绍如何自定义一个优化器并比较其与主流算法的加速效果
首先下载minst数据库作为测试数据集合minst
我们需要train-images.idx3-ubyte和train-labels.idx1-ubyte这两个文件
读取数据并且定义全连接神经网络784→100→10作为测试网络
其实优化函数的编写目前主要靠修改梯度值和学习率从而改变参数的步进值
这里我们选用Momentum来改变梯度的值再使用Rprop算法来改变学习率
Momentum算法简介
动量算法通过累积梯度来改变动量,也就是说当前梯度的值会受到历史梯度的影响
当当前梯度与历史梯度一致时,动量就会被加大,最大值为1/(1-γ),反之,如果梯度来回震荡那么动量就会被当前梯度抵消减弱。
动量更新公式:V(t)=γV(t?1)+η?(θ).J(θ)
Rprop算法简介
Rprop算法非常的直观,如果梯度方向连续增大就提高学习率,如果梯度震荡就减小学习率。使用这种方法必须给学习率增加一个安全阈值,防止学习率爆炸和学习率过低。
学习率更新公式:
if g(t)*g(t-1)>0
lr=lr*a
if g(t)*g(t-1)<0
lr=lr*b
其中学习率是为每个参数都单独设置的,a为增量,b为衰减量。显然其对平坦区域的加速效率为(a)^t,是指数级的加速效果。其对沟谷的减速效果同样为(b)^t,是指数级的衰减效果。
我们的设置
我们设置动量保留值γ为0.75,学习率衰减率b=0.55,学习率增加量a=1.05
最后定义自带的优化器与原始下降方法
最后附上我们自定义的优化器与公认最好的优化器Adma的以及RMSprop优化效果的比较
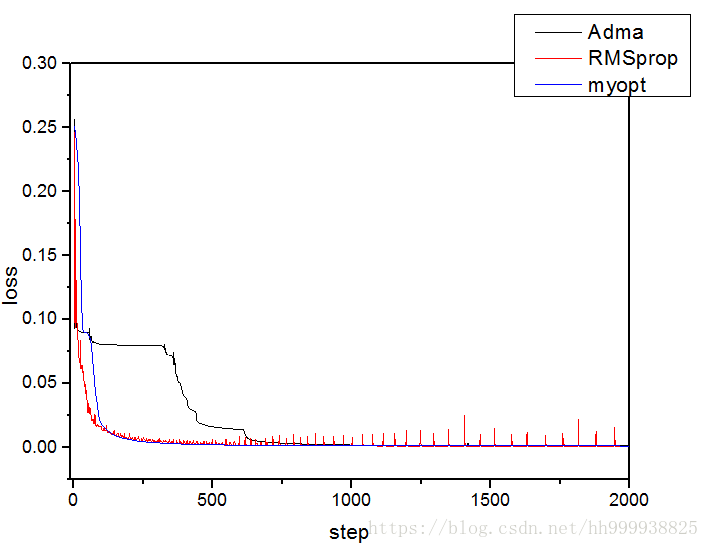
可以看出前期的下降速率RMSprop>myopt>Adma
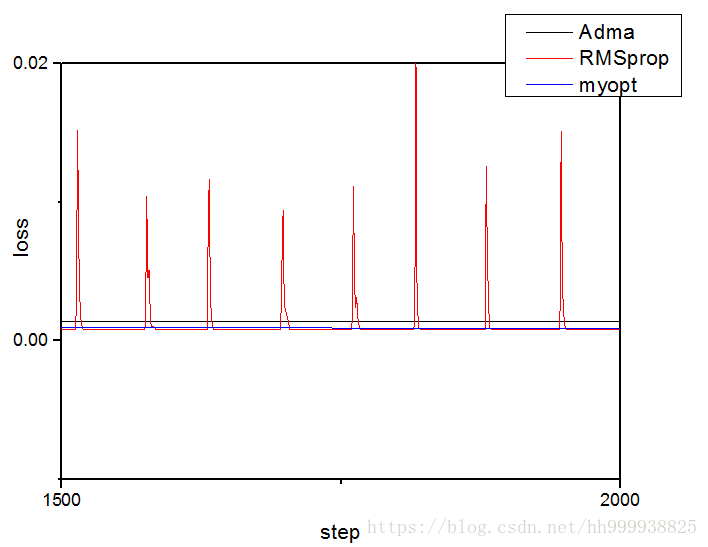
列出了后期的下降速率,在这个模型中RMSprop基本与myopt的最低值相等,但是RMSprop震荡严重而myopt基本没有震荡,这两种算法的后期优化结果在这个模型中都优于Adma


